大数据基石 HDFS分布式文件存储系统入门指南
HDFS:大数据时代的基石
在当今数据爆炸的时代,传统的文件系统已难以应对海量数据的存储与管理需求。Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)作为大数据生态系统的核心组件,以其高容错性、高吞吐量和可扩展性,为大规模数据处理提供了可靠的底层存储支持。
HDFS的核心设计思想
HDFS的设计遵循几个基本原则,这些原则使其特别适合大数据场景:
- 流式数据访问:HDFS针对一次写入、多次读取的数据访问模式进行优化,适合批量数据处理而非交互式应用
- 超大文件存储:HDFS专为存储超大文件设计,单个文件可达TB甚至PB级别
- 商用硬件部署:HDFS设计运行在低成本商用硬件上,通过软件层面的容错机制而非昂贵硬件保证可靠性
- 简单一致性模型:采用“写一次读多次”的模型,简化数据一致性问题,提高数据吞吐量
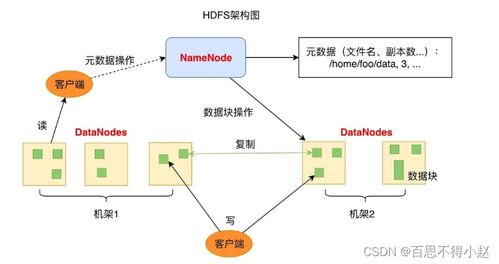
HDFS的架构与工作原理
HDFS采用主从架构,由以下核心组件构成:
NameNode(主节点)
- 存储文件系统的元数据(文件名、目录结构、文件属性等)
- 管理文件系统的命名空间
- 记录数据块(Block)到DataNode的映射关系
- 协调客户端的文件访问请求
DataNode(从节点)
- 实际存储数据块
- 响应NameNode的指令执行数据块的创建、删除和复制
- 定期向NameNode发送心跳信号和数据块报告
Secondary NameNode(辅助节点)
- 定期合并NameNode的编辑日志(EditLog)和镜像文件(FsImage)
- 协助NameNode进行元数据管理,并非NameNode的热备份
HDFS的数据处理与存储流程
数据写入过程
- 客户端向NameNode发起文件写入请求
- NameNode检查权限和文件是否存在,返回可用的DataNode列表
- 客户端将数据分块(默认128MB)并建立数据管道
- 数据块以流水线方式复制到多个DataNode(默认3副本)
- 所有DataNode确认写入成功后,客户端通知NameNode完成写入
数据读取过程
- 客户端向NameNode请求文件位置信息
- NameNode返回包含文件数据块位置信息的元数据
- 客户端直接从最近的DataNode读取数据块
- 如果读取失败,自动尝试从其他副本读取
数据容错机制
- 副本机制:每个数据块默认保存3个副本,分布在不同的机架上
- 心跳检测:DataNode定期向NameNode发送心跳信号,丢失心跳的节点被视为失效
- 数据块重新复制:当副本数量不足时,NameNode触发数据块复制
- 数据完整性校验:使用校验和(Checksum)检测数据损坏
HDFS在大数据生态系统中的角色
HDFS不仅是一个分布式文件系统,更是整个大数据处理平台的基础:
与MapReduce的集成
- 作为MapReduce的输入输出存储
- 数据本地化优化:计算任务被调度到存储数据的节点附近执行
与数据仓库工具的配合
- Hive、Impala等工具将HDFS作为底层存储
- 支持结构化和半结构化数据的存储
与流处理框架的协作
- Kafka、Flume等数据采集工具可将数据直接写入HDFS
- Spark Streaming、Flink等流处理框架可使用HDFS作为检查点存储
实践入门:HDFS基本操作
常用命令示例
`bash
# 查看HDFS目录内容
hadoop fs -ls /user
创建目录
hadoop fs -mkdir /user/data
从本地系统上传文件到HDFS
hadoop fs -put localfile.txt /user/data/
从HDFS下载文件到本地
hadoop fs -get /user/data/file.txt ./
查看文件内容
hadoop fs -cat /user/data/file.txt
删除文件
hadoop fs -rm /user/data/file.txt`
编程接口
HDFS提供了多种编程接口,包括:
- Java API(原生接口)
- HTTP REST API(通过WebHDFS)
- C语言封装接口
- 各种语言客户端库
HDFS的局限性与适用场景
适用场景
- 海量数据存储(日志文件、传感器数据、社交媒体数据等)
- 批处理数据分析
- 数据归档和备份
- 作为数据湖的基础存储层
局限性
- 不适合低延迟数据访问
- 不支持大量小文件存储
- 单点故障风险(NameNode)
- 文件修改限制(主要是追加操作)
HDFS的发展与未来
随着大数据技术的演进,HDFS也在不断发展:
高可用性改进
- NameNode高可用(HA)架构消除单点故障
- 使用ZooKeeper进行故障转移
性能优化
- 内存缓存改进(HDFS缓存)
- 纠删码技术减少存储开销
- 更高效的数据压缩支持
与新技术的融合
- 与对象存储(如S3)的集成
- 容器化部署支持
- 云原生架构适配
##
HDFS作为大数据技术的基石,为海量数据的存储和处理提供了可靠的基础设施。理解HDFS的原理和特性,是进入大数据领域的重要第一步。随着技术的不断发展,HDFS也在不断演进,但它的核心设计理念——通过分布式架构解决大规模数据存储问题——将继续影响和指导未来数据存储技术的发展方向。
对于初学者而言,建议从搭建简单的Hadoop集群开始,通过实际操作加深对HDFS的理解,为后续学习更复杂的大数据技术打下坚实基础。
如若转载,请注明出处:http://www.jngwv.com/product/18.html
更新时间:2026-05-24 08:48:57