数据存储与操作 构建可靠的数据处理与存储支持服务体系

在当今数据驱动的时代,第六章聚焦的“数据存储和操作”是信息系统的核心支柱。它涵盖了从数据采集、处理到长期存储、高效访问与管理的全过程,旨在构建稳定、安全、可扩展的数据处理与存储支持服务体系。
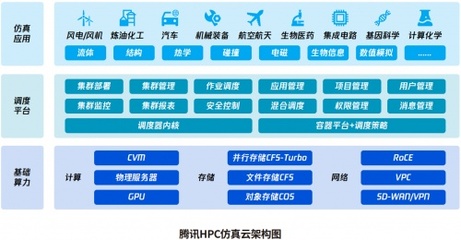
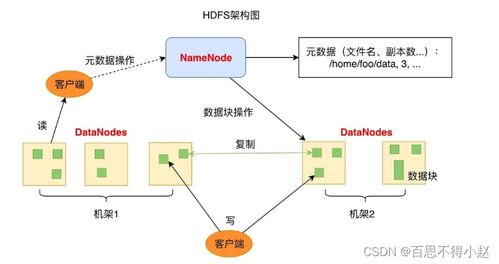
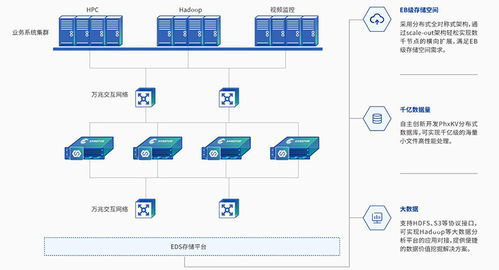
数据存储不仅是简单的数据堆积,更是经过精心设计的架构,以满足不同业务场景下的性能、可靠性和成本需求。常见的存储方案包括关系型数据库、非关系型数据库、数据仓库、数据湖以及新兴的云存储服务。关系型数据库(如MySQL、PostgreSQL)以其强一致性、事务支持和结构化查询能力,适用于需要严格数据完整性的业务系统;而非关系型数据库(如MongoDB、Redis)则在处理大规模非结构化数据、高并发读写和灵活数据模型方面表现卓越。数据仓库(如Amazon Redshift、Snowflake)专注于复杂的分析查询和历史数据洞察,而数据湖(如基于Hadoop或云原生方案)则为原始数据的集中存储和多样化分析提供了基础。
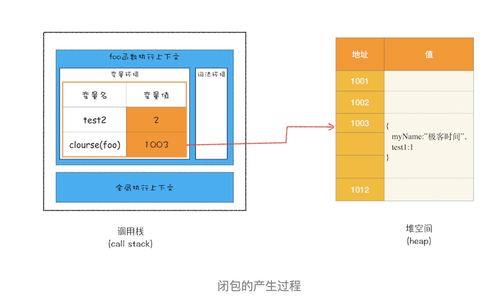
数据处理操作则涉及数据的生命周期管理,包括数据的清洗、转换、集成、备份、恢复和归档。这一过程确保了数据的质量、一致性与可用性。例如,通过ETL(提取、转换、加载)或ELT流程,可以将来自不同源头的数据整合为统一视图,支持业务决策;定期的备份和灾难恢复策略则能防范数据丢失风险,保障业务连续性。
支持服务是这一体系的重要组成,包括监控、优化、安全与合规性管理。实时监控存储系统的性能指标(如I/O延迟、吞吐量)能及时发现瓶颈;通过索引优化、查询调优和存储分层(如热数据与冷数据分离)可提升效率;加密、访问控制和审计日志等措施能有效保护数据隐私与安全,满足日益严格的法规要求(如GDPR、CCPA)。
随着云计算和人工智能的发展,数据存储与操作正变得更加自动化与智能化。云原生存储服务提供了弹性伸缩和按需付费的优势,而AI驱动的管理工具能预测存储需求、自动优化资源配置。融合边缘计算与中心云的数据处理架构将进一步扩展应用场景,支持物联网和实时分析。
构建一个强大的数据存储与操作体系,需要综合技术选型、流程设计和服务管理,以实现数据价值最大化,为组织创新与增长奠定坚实基础。
如若转载,请注明出处:http://www.jngwv.com/product/5.html
更新时间:2026-06-19 19:26:34